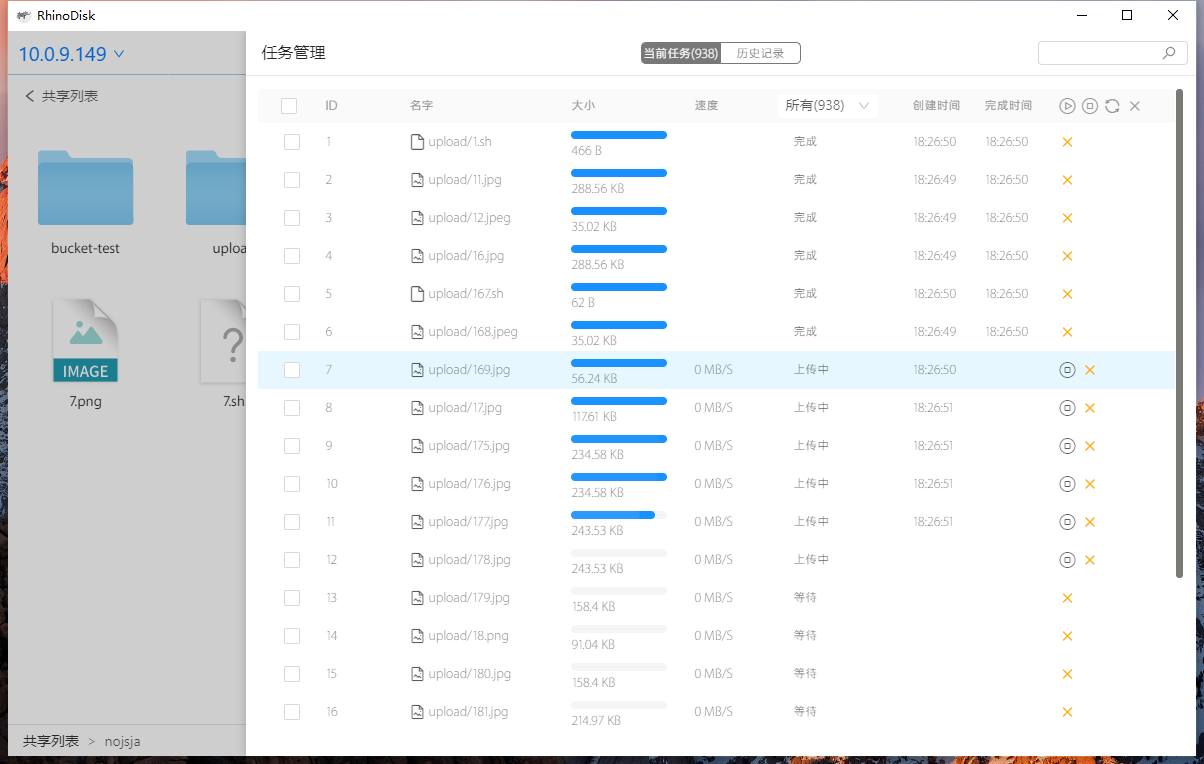
文中实现的部分工具方法正处于早期/测试阶段,仍在持续优化中,仅供参考…
I 前言
上一篇文章《基于Electron的smb客户端开发记录》 ,大致描述了整个SMB客户端开发的核心功能、实现难点、项目打包这些内容,这篇文章呢单独把其中的文件分片上传模块拿出来进行分享,提及一些与Electron主进程、渲染进程和文件上传优化相关的功能点。
II Demo运行 项目精简版 DEMO地址 ,删除了smb处理的多余逻辑,使用文件复制模拟上传流程,可直接运行体验。
demo运行时需要分别开启两个开发环境view -> service,然后才能预览界面,由于没有后端,文件默认上传(复制)到electron数据目录(在Ubuntu上是~/.config/FileSliceUpload/runtime/upload)
1 2 3 4 5 6 7 8 9 10 11 12 $: npm install $: npm start $: npm install $: npm start $: node build.js --help $: node build.js build-linux $: node build.js build-mac $: node build.js build-win
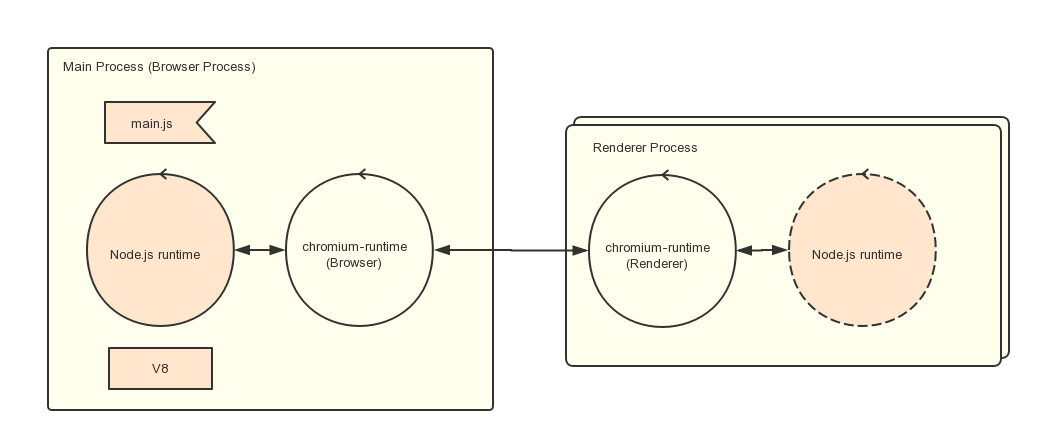
III Electron进程架构 主进程和渲染进程的区别
Electron 运行 package.json 的 main 脚本的进程被称为主进程。在主进程中运行的脚本通过创建web页面来展示用户界面,一个 Electron 应用总是有且只有一个主进程。
在普通的浏览器中,web页面通常在沙盒环境中运行,并且无法访问操作系统的原生资源。 然而 Electron 的用户在 Node.js 的 API 支持下可以在页面中和操作系统进行一些底层交互。
主进程和渲染进程之间的通信 1/2-自带方法,3-外部扩展方法
1. 使用remote远程调用
remote模块为渲染进程和主进程通信提供了一种简单方法,使用remote模块, 你可以调用main进程对象的方法, 而不必显式发送进程间消息。示例如下,代码通过remote远程调用主进程的BrowserWindows创建了一个渲染进程,并加载了一个网页地址:
1 2 3 4 const { BrowserWindow } = require ('electron' ).remote let win = new BrowserWindow ({ width : 800 , height : 600 })win.loadURL ('https://github.com' )
注意:remote底层是基于ipc的同步进程通信(同步=阻塞页面),都知道Node.js的最大特性就是异步调用,非阻塞IO,因此remote调用不适用于主进程和渲染进程频繁通信以及耗时请求的情况,否则会引起严重的程序性能问题。
2. 使用ipc信号通信
基于事件触发的ipc双向信号通信,渲染进程中的ipcRenderer可以监听一个事件通道,也能向主进程或其它渲染进程直接发送消息(需要知道其它渲染进程的webContentsId),同理主进程中的ipcMain也能监听某个事件通道和向任意一个渲染进程发送消息。webContentsId或者能够直接拿到目标进程的实例,使用方式不太灵活。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ipcMain.on (channel, listener) ipcMain.once (channel, listener) ipcMain.handle (channel, listener) ipcMain.handleOnce (channel, listener) browserWindow.webContents .send (channel, args); ipcRenderer.on (channel, listener); ipcRenderer.once (channel, listener); ipcRenderer.sendSync (channel, args); ipcRenderer.invoke (channel, args); ipcRenderer.sendTo (webContentsId, channel, ...args); ipcRenderer.sendToHost (channel, ...args)
3. 使用electron-re 进行多向通信
electron-re 是之前开发的一个处理electron进程间通信的工具,基于自带的ipc信号通信进行了封装,已经发布为npm组件。主要功能是在Electron已有的Main Process主进程 和 Renderer Process渲染进程概念的基础上独立出一个单独的Service 逻辑。Service即不需要显示界面的后台进程,它不参与UI交互,单独为主进程或其它渲染进程提供服务,它的底层实现为一个允许node注入和remote调用的渲染窗口进程。
比如在你看过一些Electron最佳实践中,耗费cpu的操作是不建议被放到主进程中处理的,这时候就可以将这部分耗费cpu的操作编写成一个单独的js文件,然后使用Service构造函数以这个js文件的地址path为参数构造一个Service实例,并通过electron-re提供的MessageChannel通信工具在主进程、渲染进程、service进程之间任意发送消息,可以参考以下示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 const { BrowserService , MessageChannel } = require ('electron-re' ); const isInDev = process.env .NODE_ENV === 'dev' ;... app.whenReady ().then (async () => { const myService = new BrowserService ('app' , 'path/to/app.service.js' ); const myService2 = new BrowserService ('app2' , 'path/to/app2.service.js' ); await myService.connected (); await myService2.connected (); if (isInDev) myService.openDevTools (); MessageChannel .send ('app' , 'channel1' , { value : 'test1' }); MessageChannel .invoke ('app' , 'channel2' , { value : 'test2' }).then ((response ) => { console .log (response); }); MessageChannel .on ('channel3' , (event, response ) => { console .log (response); }); MessageChannel .handle ('channel4' , (event, response ) => { console .log (response); return { res : 'channel4-res' }; }); });
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 const { ipcRenderer } = require ('electron' );const { MessageChannel } = require ('electron-re' );MessageChannel .on ('channel1' , (event, result ) => { console .log (result); }); MessageChannel .handle ('channel2' , (event, result ) => { console .log (result); return { response : 'channel2-response' } }); MessageChannel .invoke ('app2' , 'channel3' , { value : 'channel3' }).then ((event, result ) => { console .log (result); }); MessageChannel .send ('app' , 'channel4' , { value : 'channel4' });
1 2 3 4 5 6 7 8 9 10 11 12 13 MessageChannel .handle ('channel3' , (event, result ) => { console .log (result); return { response : 'channel3-response' } }); MessageChannel .once ('channel4' , (event, result ) => { console .log (result); }); MessageChannel .send ('main' , 'channel3' , { value : 'channel3' });MessageChannel .invoke ('main' , 'channel4' , { value : 'channel4' });
4)renderer process window 1 2 3 4 5 6 7 8 const { ipcRenderer } = require ('electron' );const { MessageChannel } = require ('electron-re' );MessageChannel .send ('app' , ...);MessageChannel .invoke ('app2' , ...);MessageChannel .send ('main' , ...);MessageChannel .invoke ('main' , ...);
IV 文件上传架构 文件上传主要逻辑控制部分是前端的JS脚本代码,位于主窗口所在的render渲染进程,负责用户获取系统目录文件、生成上传任务队列、动态展示上传任务列表详情、任务列表的增删查改等;主进程Electron端的Node.js代码主要负责响应render进程的控制命令进行文件上传任务队列数据的增删查改、上传任务在内存和磁盘的同步、文件系统的交互、系统原生组件调用等。
文件上传源和上传目标 在用户界面上使用Input组件获取到的FileList(HTML5 API,用于web端的简单文件操作)即为上传源;
上传目标地址是远端集群某个节点的smb服务,因为Node.js NPM生态对smb的支持有限,目前并未发现一个可以支持通过smb协议进行文件分片上传的npm库,所以考虑使用Node.js的FS API进行文件分段读取然后将分片数据逐步增量写入目标地址来模拟文件分片上传过程,从而实现在界面上单个大文件上传任务的启动、暂停、终止和续传等操作,所以这里的解决方案是使用Windows UNC命令连接后端共享后,可以像访问本地文件系统一样访问远程一个远程smb共享路径,比如文件路径\\[host]\[sharename]\file1上的file1在执行了unc连接后就可以通过Node.js FS API进行操作,跟操作本地文件完全一致。整个必须依赖smb协议的上传流程即精简为将本地拿到的文件数据复制到可以在本地访问的另一个smb共享路径这一流程,而这一切都得益于Windows UNC命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 _uncCommandConnect_Windows_NT ({ host, username, pwd } ) { const { isThirdUser, nickname, isLocalUser } = global .ipcMainProcess .userModel .info ; const commandUse = `net use \\\\${host} \\ipc$ "${pwd} " /user:"${username} "` ; return new Promise ((resolve ) => { this .sudo .exec (commandUse).then ((res ) => { resolve ({ code : 200 , }); }).catch ((err ) => { resolve ({ code : 600 , result : global .lang .upload .unc_connection_failed }); }); }); }
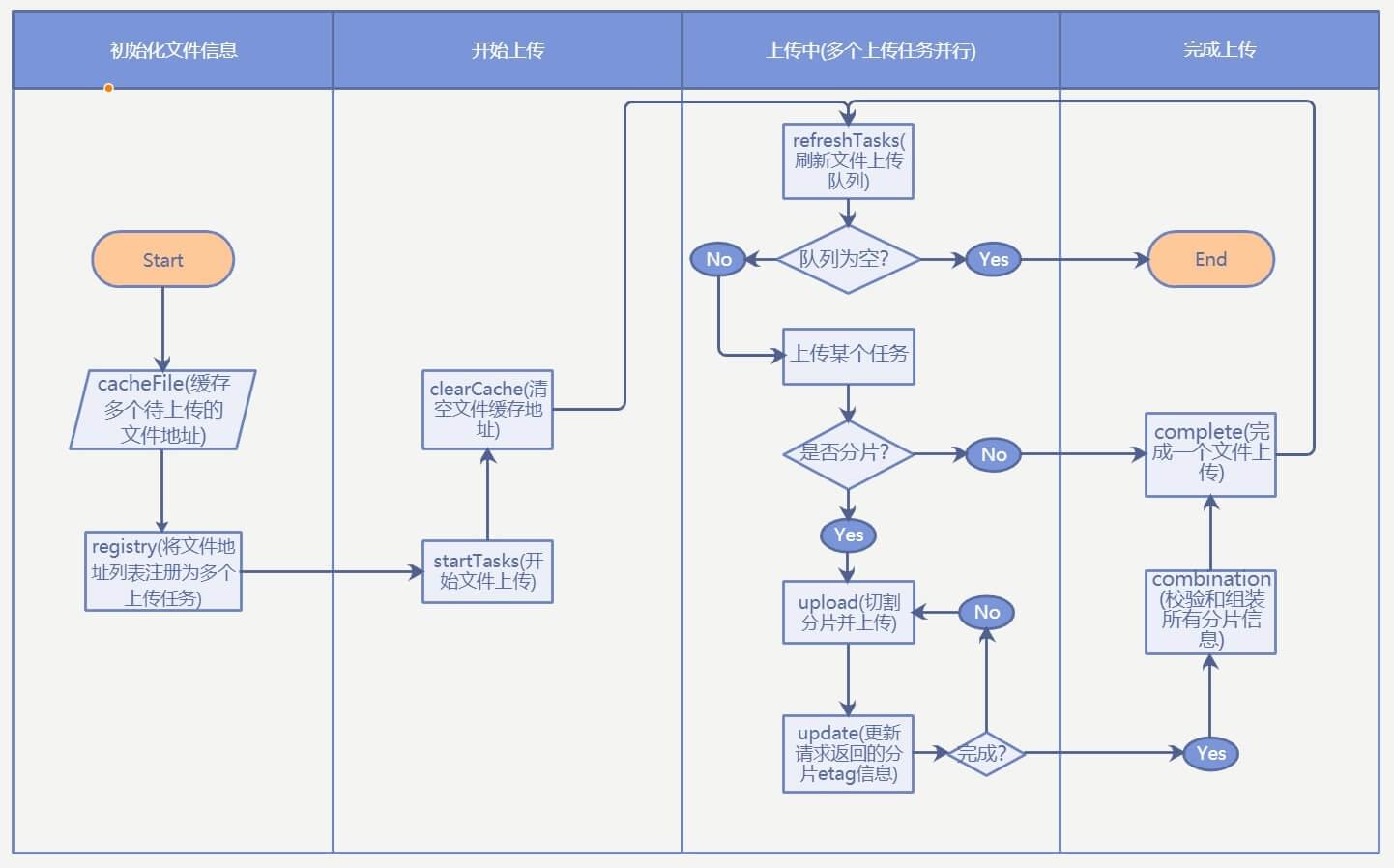
上传流程概述 下图描述了整个前端部分的控制逻辑:
页面上使用<Input />组件拿到FileList对象(Electron环境下拿到的File对象会额外附加一个path属性指明文件位于系统的绝对路径) 缓存拿到的FileList,等待点击上传按钮后开始读取FileList列表并生成自定义的File文件对象数组用于存储上传任务列表信息 页面调用init请求附带上选中的文件信息初始化文件上传任务 Node.js拿到init请求附带的文件信息后,将所有信息存入临时存放在内存中的文件上传列表中,并尝试打开待上传文件的文件描述符用于即将开始的文件切片分段上传工作,最后返回给页面上传任务ID,Node.js端完成初始化处理 页面拿到init请求成功的回调后,存储返回的上传任务ID,并将该文件加入文件待上传队列,在合适的时机开始上传,开始上传的时候向Node.js端发送upload请求,同时请求附带上任务ID和当前的分片索引值(表示需要上传第几个文件分片) Node.js拿到upload请求后根据携带的任务ID读取内存中的上传任务信息,然后使用第二步打开的文件描述符和分片索引对本地磁盘中的目标文件进行分片切割,最后使用FS API将分片递增写入目标位置,即本地可直接访问的SMB共享路径 upload请求成功后页面判断是否已经上传完所有分片,如果完成则向Node.js发送complete请求,同时携带上任务ID Node.js根据任务ID获取文件信息,关闭文件描述符,更新文件上传任务为上传完成状态 界面上传任务列表全部完成后,向后端发送sync请求,把当前任务上传列表同步到历史任务(磁盘存储)中,表明当前列表中所有任务已经完成 Node.js拿到sync请求后,把内存中存储的所有文件上传列表信息写入磁盘,同时释放内存占用,完成一次列表任务上传 Node.js实现的文件分片管理工厂 文件初始化的时候调用open方法临时存储文件描述符和文件绝对路径的映射关系; 文件上传的时候调用read方法根据文件读取位置、读取容量大小进行分片切割; 文件上传完成的时候调用close关闭文件描述符; 三个方法均通过文件绝对路径path参数建立关联:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 exports .readFileBlock = () => { const fdStore = {}; const smallFileMap = {}; return { open : (path, size, minSize=1024 *2 ) => { return new Promise ((resolve ) => { try { if (size <= minSize) { smallFileMap[path] = true ; return resolve ({ code : 200 , result : { fd : null } }); } fs.open (path, 'r' , (err, fd ) => { if (err) { console .trace (err); resolve ({ code : 601 , result : err.toString () }); } else { fdStore[path] = fd; resolve ({ code : 200 , result : { fd : fdStore[path] } }); } }); } catch (err) { console .trace (err); resolve ({ code : 600 , result : err.toString () }); } }) }, read : (path, position, length ) => { return new Promise ((resolve, reject ) => { const callback = (err, data ) => { if (err) { resolve ({ code : 600 , result : err.toString () }); } else { resolve ({ code : 200 , result : data }); } }; try { if (smallFileMap[path]) { fs.readFile (path, (err, buffer ) => { callback (err, buffer); }); } else { if (length === 0 ) return callback (null , '' ); fs.read (fdStore[path], Buffer .alloc (length), 0 , length, position, function (err, readByte, readResult ){ callback (err, readResult); }); } } catch (err) { console .trace (err); resolve ({ code : 600 , result : err.toString () }); } }); }, close : (path ) => { return new Promise ((resolve ) => { try { if (smallFileMap[path]) { delete smallFileMap[path]; resolve ({ code : 200 }); } else { fs.close (fdStore[path], () => { resolve ({code : 200 }); delete fdStore[path]; }); } } catch (err) { console .trace (err); resolve ({ code : 600 , result : err.toString () }); } }); }, fdStore } }
V 基于Electron的文件上传卡顿优化踩坑 优化是一件头大的事儿,因为你需要先通过很多测试手法找到现有代码的性能瓶颈,然后编写优化解决方案。我觉得找到性能瓶颈这一点就比较难,因为是自己写的代码所以容易陷入一些先入为主的刻板思考模式。不过最最主要的一点还是你如果自己都弄不清楚你使用的技术栈的话,那就无从谈起优化,所以前面有很大篇幅分析了Electron进程方面的知识以及梳理了整个上传流程。
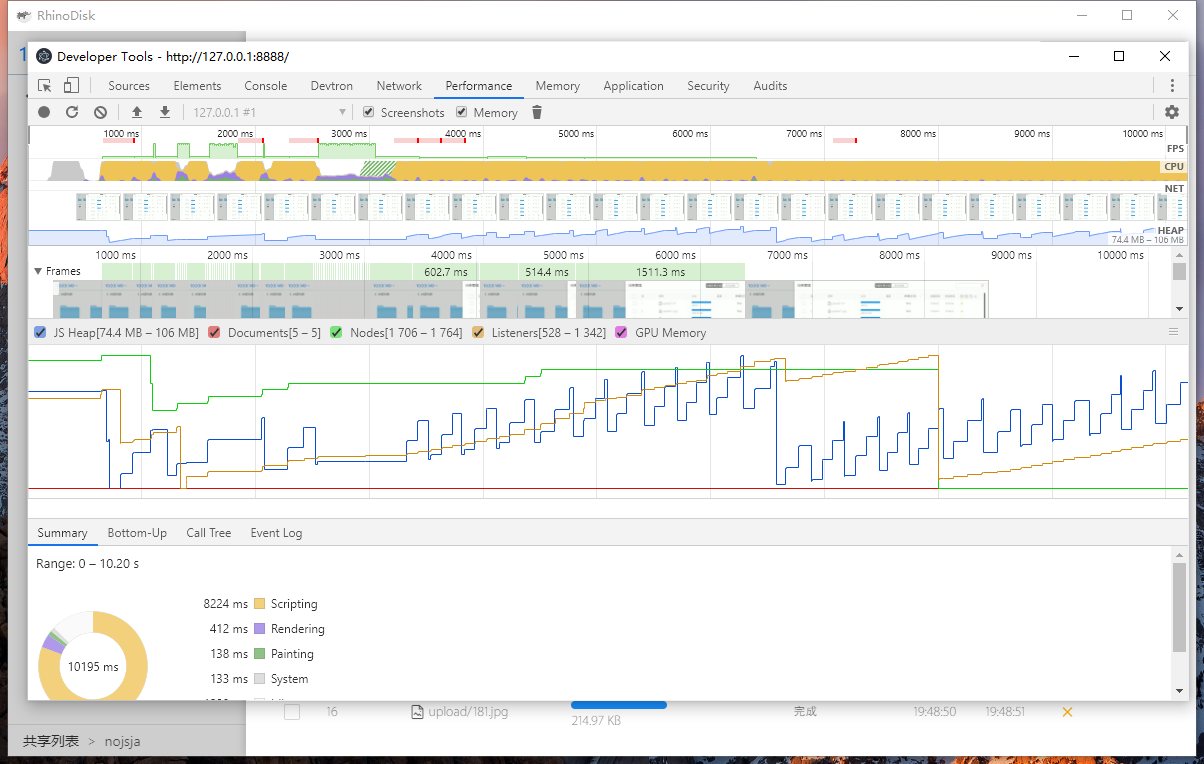
在文件上传过程中打开性能检测工具Performance进行录制,分析整个流程:
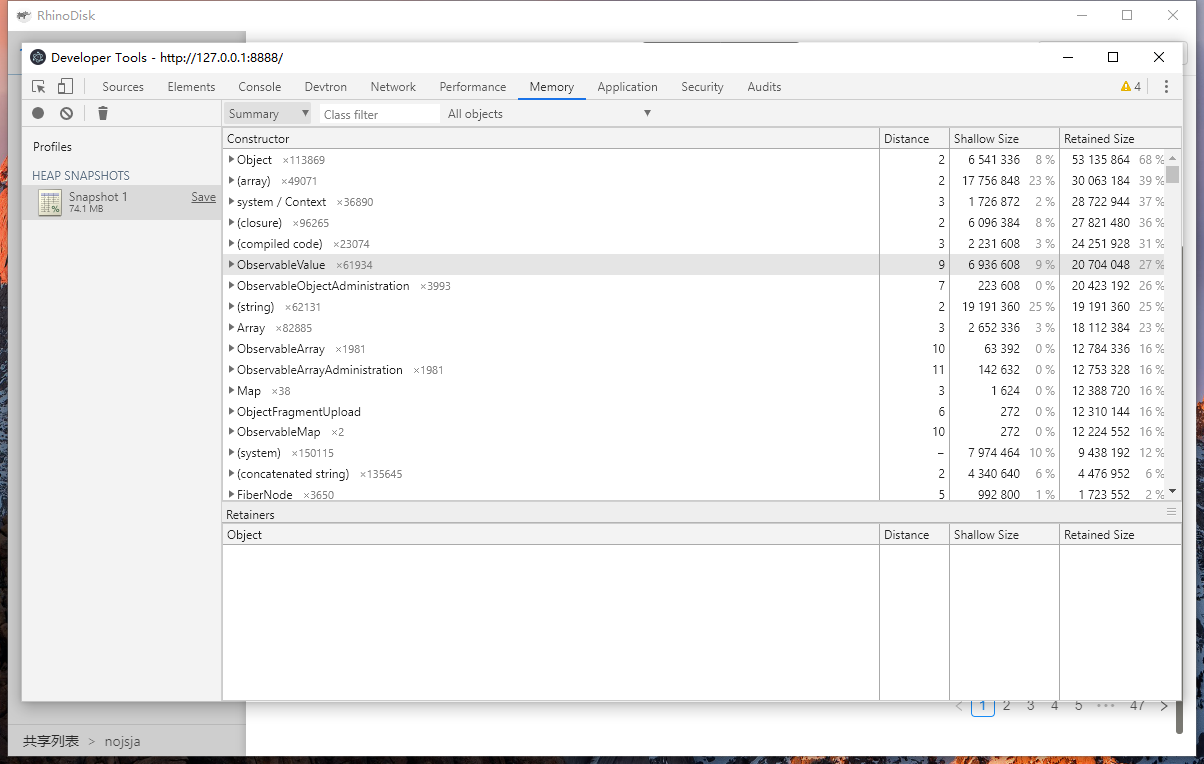
在文件上传过程中打开内存工具Memory进行快照截取分析一个时刻的内存占用情况:
第一次尝试解决问题:替换Antd Table组件 在编写完成文件上传模块后,初步进行了压力测试,结果发现添加1000个文件上传任务到任务队列,且同时上传的文件上传任务数量为6时,上下滑动查看文件上传列表时出现了卡顿的情况,这种卡顿不局限于某个界面组件的卡顿,而且当前窗口的所有操作都卡了起来,初步怀疑是Antd Table组件引起的卡顿,因为Antd Table组件是个很复杂的高阶组件,在处理大量的数据时可能会有性能问题,遂我将Antd Table组件换成了原生的table组件,且Table列表只显示每个上传任务的任务名,其余的诸如上传进度这些都不予显示,从而想避开这个问题。令人吃惊的是测试结果是即使换用了原生Table组件,卡顿情况仍然毫无改善!
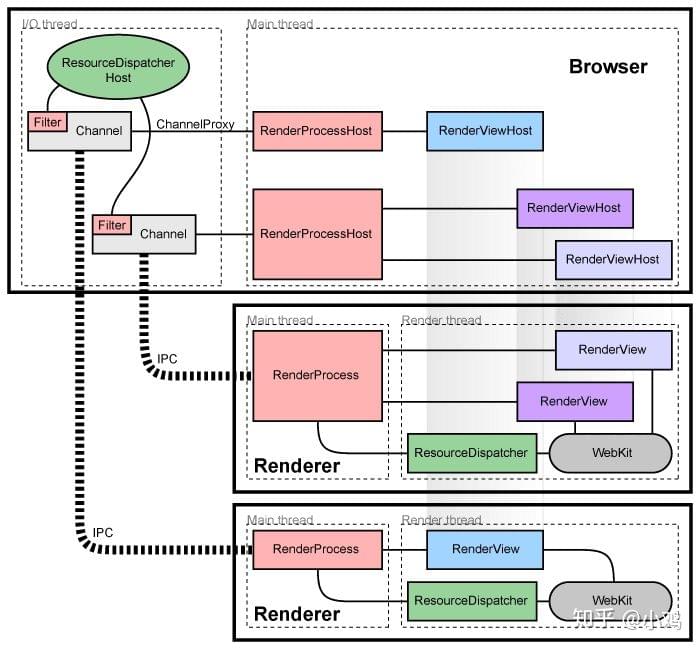
第二次尝试解决问题:改造Electron主进程同步阻塞代码 先看下chromium的架构图,每个渲染进程都有一个全局对象RenderProcess,用来管理与父浏览器进程的通信,同时维护着一份全局状态。浏览器进程为每个渲染进程维护一个RenderProcessHost对象,用来管理浏览器状态和与渲染进程的通信。浏览器进程和渲染进程使用Chromium的IPC系统进行通信。在chromium中,页面渲染时,UI进程需要和main process不断的进行IPC同步,若此时main process忙,则UIprocess就会在IPC时阻塞。
综上所述:如果主进程持续进行消耗CPU时间的任务或阻塞同步IO的任务的话,主进程就会在一定程度上阻塞,从而影响主进程和各个渲染进程之间的IPC通信,IPC通信有延迟或是受阻,自然渲染界面的UI绘制和更新就会呈现卡顿的状态。
我分析了一下Node.js端的文件任务管理的代码逻辑,把一些操作诸如获取文件大小、获取文件类型和删除文件这类的同步阻塞IO调用都换成了Node.js提倡的异步调用模式,即FS callback或Fs Promise链式调用。改动后发现卡顿情况改善不明显,遂进行了第三次尝试。
第三次尝试解决问题:编写Node.js进程池分离上传任务管理逻辑 这次是大改😕
1. 简单实现了node.js进程池 ChildProcessPool.class.js ,主要逻辑是使用Node.js的child_process模块(具体使用请看文档 ) 创建指定数量的多个子进程,外部通过进程池获取一个可用的进程,在进程中执行需要的代码逻辑,而在进程池内部其实就是按照顺序依次将已经创建的多个子进程中的某一个返回给外部调用即可,从而避免了其中某个进程被过度使用,省略代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 ... class ChildProcessPool { constructor ({ path, max=6 , cwd, env } ) { this .cwd = cwd || process.cwd (); this .env = env || process.env ; this .inspectStartIndex = 5858 ; this .callbacks = {}; this .pidMap = new Map (); this .collaborationMap = new Map (); this .forked = []; this .forkedPath = path; this .forkIndex = 0 ; this .forkMaxIndex = max; } dataRespond = (data, id ) => { ... } dataRespondAll = (data, id ) => { ... } getForkedFromPool (id="default" ) { let forked; if (!this .pidMap .get (id)) { if (this .forked .length < this .forkMaxIndex ) { this .inspectStartIndex ++; forked = fork ( this .forkedPath , this .env .NODE_ENV === "development" ? [`--inspect=${this .inspectStartIndex} ` ] : [], { cwd : this .cwd , env : { ...this .env , id }, } ); this .forked .push (forked); forked.on ('message' , (data ) => { const id = data.id ; delete data.id ; delete data.action ; this .onMessage ({ data, id }); }); } else { this .forkIndex = this .forkIndex % this .forkMaxIndex ; forked = this .forked [this .forkIndex ]; } if (id !== 'default' ) this .pidMap .set (id, forked.pid ); if (this .pidMap .values .length === 1000 ) console .warn ('ChildProcessPool: The count of pidMap is over than 1000, suggest to use unique id!' ); this .forkIndex += 1 ; } else { forked = this .forked .filter (f =>pid === this .pidMap .get (id))[0 ]; if (!forked) throw new Error (`Get forked process from pool failed! the process pid: ${this .pidMap.get(id)} .` ); } return forked; } onMessage ({ data, id } ) {...} send (taskName, params, givenId="default" ) { if (givenId === 'default' ) throw new Error ('ChildProcessPool: Prohibit the use of this id value: [default] !' ) const id = getRandomString (); const forked = this .getForkedFromPool (givenId); return new Promise (resolve => this .callbacks [id] = resolve; forked.send ({action : taskName, params, id }); }); } sendToAll (taskName, params ) {...} }
1)使用send和sendToAll方法向子进程发送消息,前者是向某个进程发送,如果请求参数指定了id则表明需要明确使用之前与此id建立过映射的某个进程,并期望拿到此进程的回应结果;后者是向进程池中的所有进程发送信号,并期望拿到所有进程返回的结果(供调用者外部调用 )。
2)其中dataRespond和dataRespondAll方法对应上面的两个信号发送方法的进程返回数据回调函数,前者拿到进程池中指定的某个进程的回调结果,后者拿到进程池中所有进程的回调结果(进程池内部方法,调用者无需关注 )。
3)getForkedFromPool方法是从进程池中拿到一个进程,如果进程池还没有一个子进程或是已经创建的子进程数量小于设置的可创建子进程数最大值,那么会优先新创建一个子进程放入进程池,然后返回这个子进程以供调用(进程池内部方法,调用者无需关注 )。
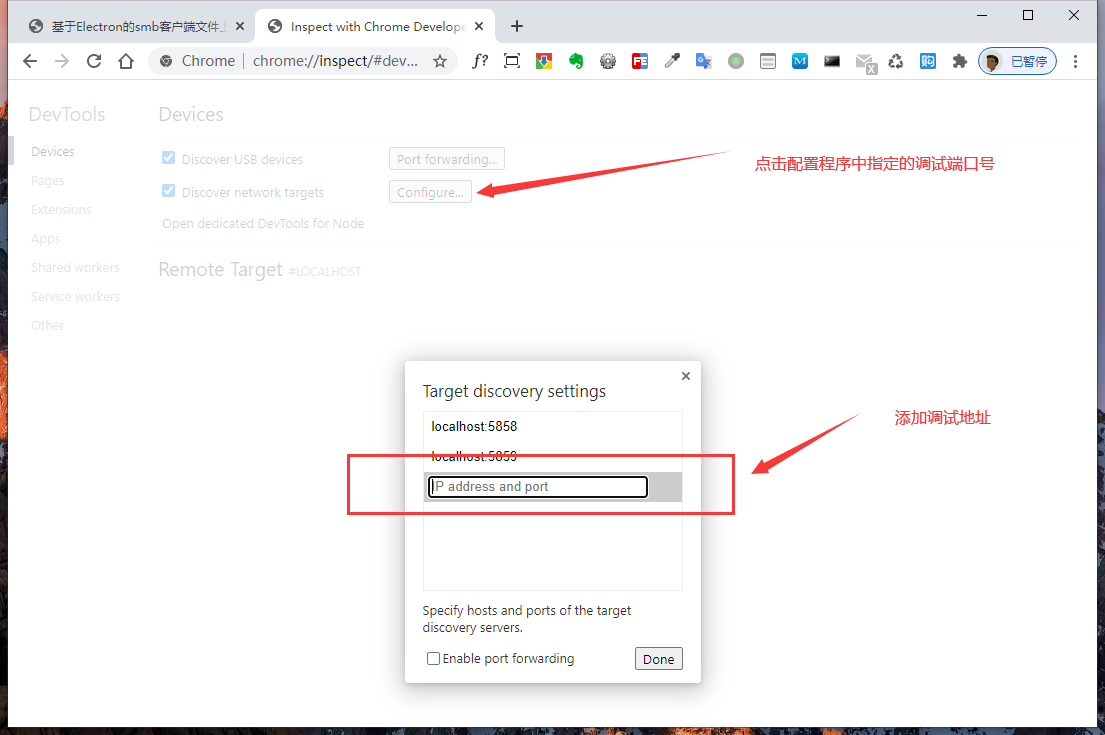
4)getForkedFromPool方法中值得注意的是这行代码:this.env.NODE_ENV === "development" ? [`--inspect=${this.inspectStartIndex}`] : [],使用Node.js运行js脚本时加上- -inspect=端口号 参数可以开启所运行进程的远程调试端口,多进程程序状态追踪往往比较困难,所以采取这种方式后可以使用浏览器Devtools单独调试每个进程(具体可以在浏览器输入地址:chrome://inspect/#devices然后打开调试配置项,配置我们这边指定的调试端口号,最后点击蓝字Open dedicated DevTools for Node就能打开一个调试窗口,可以对代码进程断点调试、单步调试、步进步出、运行变量查看等操作,十分便利!)。
2. 分离子进程通信逻辑和业务逻辑 ProcessHost.class.js ,我把它称为进程事务管理中心,主要功能是使用api诸如 - ProcessHost.registry(taskName, func)来注册多种任务,然后在主进程中可以直接使用进程池获取某个进程后向某个任务发送请求并取得Promise对象以拿到进程回调返回的数据,从而避免在我们的子进程执行文件中编写代码时过度关注进程之间数据的通信。进程事务管理中心的话我们就需要使用process.send来向一个进程发送消息并在另一个进程中使用process.on('message', processor)处理消息。需要注意的是如果注册的task任务是异步的则需要返回一个Promise对象而不是直接return数据,简略代码如下:
1)registry用于子进程向事务中心注册自己的任务 2)unregistry用于取消任务注册 3)handleMessage处理进程接收到的消息并根据action参数调用某个任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class ProcessHost { constructor ( this .tasks = { }; this .handleEvents (); process.on ('message' , this .handleMessage .bind (this )); } handleEvents ( handleMessage ({ action, params, id } ) { if (this .tasks [action]) { this .tasks [action](params) .then (rsp => process.send ({ action, error : null , result : rsp || {}, id }); }) .catch (error => process.send ({ action, error, result : error || {}, id }); }); } else { process.send ({ action, error : new Error (`ProcessHost: processor for action-[${action} ] is not found!` ), result : null , id, }); } } registry (taskName, processor ) { if (this .tasks [taskName]) console .warn (`ProcesHost: the task-${taskName} is registered!` ); if (typeof processor !== 'function' ) throw new Error ('ProcessHost: the processor must be a function!' ); this .tasks [taskName] = function (params ) { return new Promise ((resolve, reject ) => { Promise .resolve (processor (params)) .then (rsp => resolve (rsp); }) .catch (error => reject (error); }); }) } return this ; }; unregistry (taskName ) {...}; disconnect (disconnect (); } exit (exit (); } } global .processHost = global .processHost || new ProcessHost ();module .exports = global .processHost ;
3. ChildProcessPool和ProcessHost的配合使用 demo
|——path参数为可执行文件路径 |——max指明进程池创建的最大子进程实例数量 |——env为传递给子进程的环境变量 1 2 3 4 5 6 7 8 9 10 ... const ChildProcessPool = require ('path/to/ChildProcessPool.class' );global .ipcUploadProcess = new ChildProcessPool ({ path : path.join (app.getAppPath (), 'app/services/child/upload.js' ), max : 3 , env : { lang : global .lang , NODE_ENV : nodeEnv } }); ...
2)service.js (in main processs) 例子:使用进程池来发送初始化分片上传请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 init ({ username, host, file, abspath, sharename, fragsize, prefix = '' } ) { const date = Date .now (); const uploadId = getStringMd5 (date + file.name + file.type + file.size ); let size = 0 ; return new Promise ((resolve ) => { this .getUploadPrepath .then ((pre ) => { return global .ipcUploadProcess .send ( 'init-works' , { username, host, sharename, pre, prefix, size : file.size , name : file.name , abspath, fragsize, record : { host, filename : path.join (prefix, file.name ), size, fragsize, abspath, startime : getTime (new Date ().getTime ()), endtime : '' , uploadId, index : 0 , total : Math .ceil (size / fragsize), status : 'uploading' } }, uploadId ) }) .then ((rsp ) => { resolve ({ code : rsp.error ? 600 : 200 , result : rsp.result , }); }).catch (err => resolve ({ code : 600 , result : err.toString () }); }); }); }
3)child.js (in child process) 使用事务管理中心处理消息child.js即为创建进程池时传入的path参数所在的nodejs脚本代码,在此脚本中我们注册多个任务来处理从进程池发送过来的消息。
uploadStore - 主要用于在内存中维护整个文件上传列表,对上传任务列表进行增删查改操作(cpu耗时操作) fileBlock - 利用FS API操作文件,比如打开某个文件的文件描述符、根据描述符和分片索引值读取一个文件的某一段Buffer数据、关闭文件描述符等等。虽然都是异步IO读写,对性能影响不大,不过为了整合nodejs端上传处理流程也将其一同纳入了子进程中管理,具体可以查看源码进行了解:源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 const fs = require ('fs' );const fsPromise = fs.promises ;const path = require ('path' );const utils = require ('./child.utils' );const { readFileBlock, uploadRecordStore, unlink } = utils;const ProcessHost = require ('./libs/ProcessHost.class' );const fileBlock = readFileBlock ();const uploadStore = uploadRecordStore ();global .lang = process.env .lang ;ProcessHost .registry ('init-works' , (params ) => { return initWorks (params); }) .registry ('upload-works' , (params ) => { return uploadWorks (params); }) .registry ('close' , (params ) => { return close (params); }) .registry ('record-set' , (params ) => { uploadStore.set (params); return { result : null }; }) .registry ('record-get' , (params ) => { return uploadStore.get (params); }) .registry ('record-get-all' , (params ) => { return (uploadStore.getAll (params)); }) .registry ('record-update' , (params ) => { uploadStore.update (params); return ({result : null }); }) .registry ('record-remove' , (params ) => { uploadStore.remove (params); return { result : null }; }) .registry ('record-reset' , (params ) => { uploadStore.reset (params); return { result : null }; }) .registry ('unlink' , (params ) => { return unlink (params); }); function initWorks ({username, host, sharename, pre, prefix, name, abspath, size, fragsize, record } ) { const remotePath = path.join (pre, prefix, name); return new Promise ((resolve, reject ) => { new Promise ((reso ) => fsPromise.unlink (remotePath).then (reso).catch (reso)) .then (() => { const dirs = utils.getFileDirs ([path.join (prefix, name)]); return utils.mkdirs (pre, dirs); }) .then (() => fileBlock.open (abspath, size)) .then ((rsp ) => { if (rsp.code === 200 ) { const newRecord = { ...record, size, remotePath, username, host, sharename, startime : utils.getTime (new Date ().getTime ()), total : Math .ceil (size / fragsize), }; uploadStore.set (newRecord); return newRecord; } else { throw new Error (rsp.result ); } }) .then (resolve) .catch (error => reject (error.toString ()); }); }) } ...
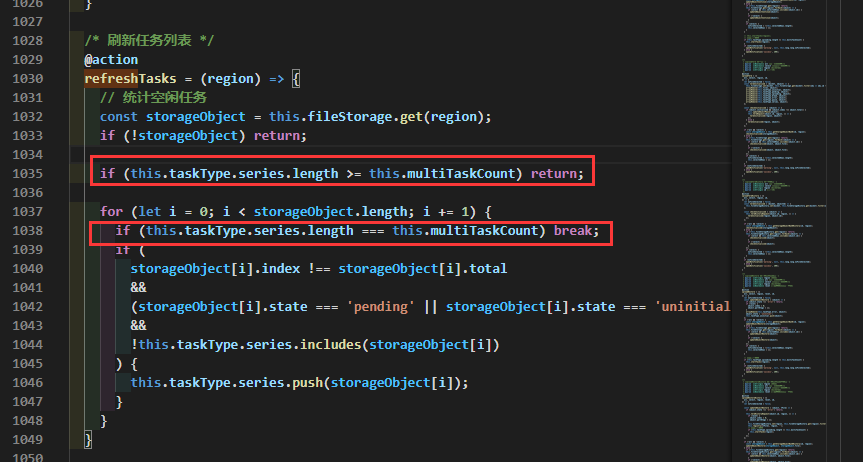
第四次尝试解决问题:重新审视渲染进程前端代码 很遗憾,第三次优化对卡顿的改善依然不明显,我开始怀疑是否是前端代码直接影响的渲染进程卡顿,毕竟前端并非采用懒加载模式进行文件载入上传的(这一怀疑之前被我否定,因为前端代码完全沿用了之前浏览器端对象存储文件分片上传开发时的逻辑,而在对象存储文件上传中并未察觉到界面卡顿,属实奇怪)。摒弃了先入为主的思想,其实Electron跟浏览器环境还是有些不同,不能排除前端代码就没有问题。 在详细查看了可能耗费CPU计算的代码逻辑后,发现有一段关于刷新上传任务的函数refreshTasks,主要逻辑是遍历所有未经上传文件原始对象数组,然后选取固定某个数量的文件(数量取决于设置的同时上传任务个数)放入待上传文件列表中,我发现如果待上传文件列表的文件数量 = 设置的同时上传任务个数 的情况下就不用继续遍历剩下的文件原始对象数组了。就是少写了这个判断条件导致refreshTasks这个频繁操作的函数在每次执行时可能多执行数千遍for循环内层判断逻辑(具体执行次数呈O(n)次增长,n为当前任务列表任务数量)。 加上一行检测逻辑代码后,之前1000个上传任务增长到10000个左右都不会太卡了,虽然还有略微卡顿,但没有到不能使用的程度,后续还有优化空间!
总结 第一次把Electron技术应用到实际项目中,踩了挺多坑:render进程和主进程通信的问题、跨平台兼容的问题、多平台打包的问题、窗口管理的问题… 总之获得了很多经验,也整理出了一些通用解决方法。