Contents
I. 前言
本文论点主要面向 Node.js 开发语言
>> Show Me Code,目前代码正在 dev 分支,已完成单元测试,尚待测试所有场景。
>> 建议通读 Node.js 官方文档 -【不要阻塞事件循环】
Node.js 即服务端 Javascript,得益于宿主环境的不同,它拥有比在浏览器上更多的能力。比如:完整的文件系统访问权限、网络协议、套接字编程、进程和线程操作、C++ 插件源码级的支持、Buffer 二进制、Crypto 加密套件的天然支持。
Node.js 的是一门单线程的语言,它基于 V8 引擎开发,v8 在设计之初是在浏览器端对 JavaScript 语言的解析运行引擎,其最大的特点是单线程,这样的设计避免了一些多线程状态同步问题,使得其更轻量化易上手。
一、名词定义
1. 进程
学术上说,进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。我们这里将进程比喻为工厂的车间,它代表 CPU 所能处理的单个任务。任一时刻,CPU 总是运行一个进程,其他进程处于非运行状态。
进程具有以下特性:
- 进程是拥有资源的基本单位,资源分配给进程,同一进程的所有线程共享该进程的所有资源;
- 进程之间可以并发执行;
- 在创建或撤消进程时,系统都要为之分配和回收资源,与线程相比系统开销较大;
- 一个进程可以有多个线程,但至少有一个线程;
2. 线程
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。
后来,随着计算机的发展,对 CPU 的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元。这里把线程比喻一个车间的工人,即一个车间可以允许由多个工人协同完成一个任务,即一个进程中可能包含多个线程。
线程具有以下特性:
- 线程作为调度和分配的基本单位;
- 多个线程之间也可并发执行;
- 线程是真正用来执行程序的,执行计算的;
- 线程不拥有系统资源,但可以访问隶属于进程的资源,一个线程只能属于一个进程;
Node.js 的多进程有助于充分利用 CPU 等资源,Node.js 的多线程提升了单进程上任务的并行处理能力。
在 Node.js 中,每个 worker 线程都有他自己的 V8 实例和事件循环机制 (Event Loop)。但是,和进程不同,workers 之间是可以共享内存的。
二、Node.js 异步机制
1. Node.js 内部线程池、异步机制以及宏任务优先级划分
Node.js 的单线程是指程序的主要执行线程是单线程,这个主线程同时也负责事件循环。而其实语言内部也会创建线程池来处理主线程程序的 网络 IO / 文件 IO / 定时器 等调用产生的异步任务。一个例子就是定时器 Timer 的实现:在 Node.js 中使用定时器时,Node.js 会开启一个定时器线程进行计时,计时结束时,定时器回调函数会被放入位于主线程的宏任务队列。当事件循环系统执行完主线程同步代码和当前阶段的所有微任务时,该回调任务最后再被取出执行。所以 Node.js 的定时器其实是不准确的,只能保证在预计时间时我们的回调任务被放入队列等待执行,而不是直接被执行。
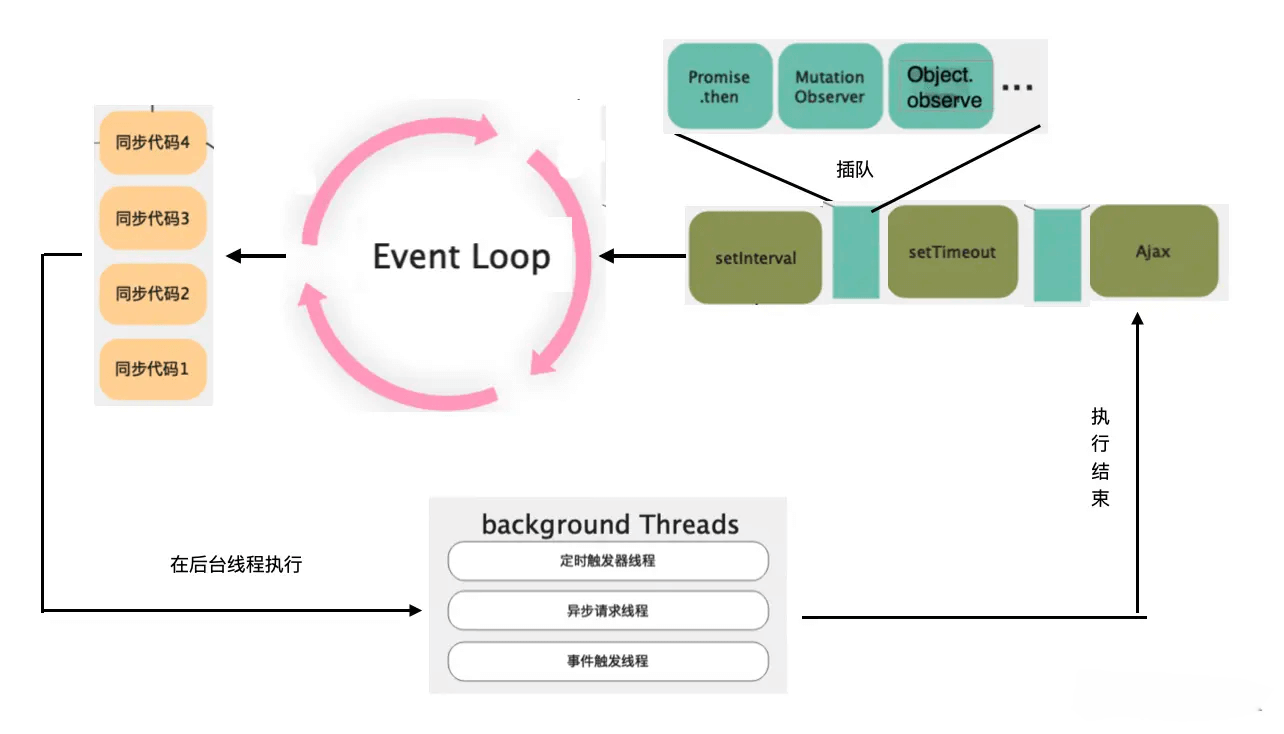
多线程机制配合 Node.js 的 evet loop 事件循环系统让开发者在一个线程内就能够使用异步机制,包括定时器、IO、网络请求。但为了实现高响应度的高性能服务器,Node.js 的 Event Loop 在宏任务上进一步划分了优先级。
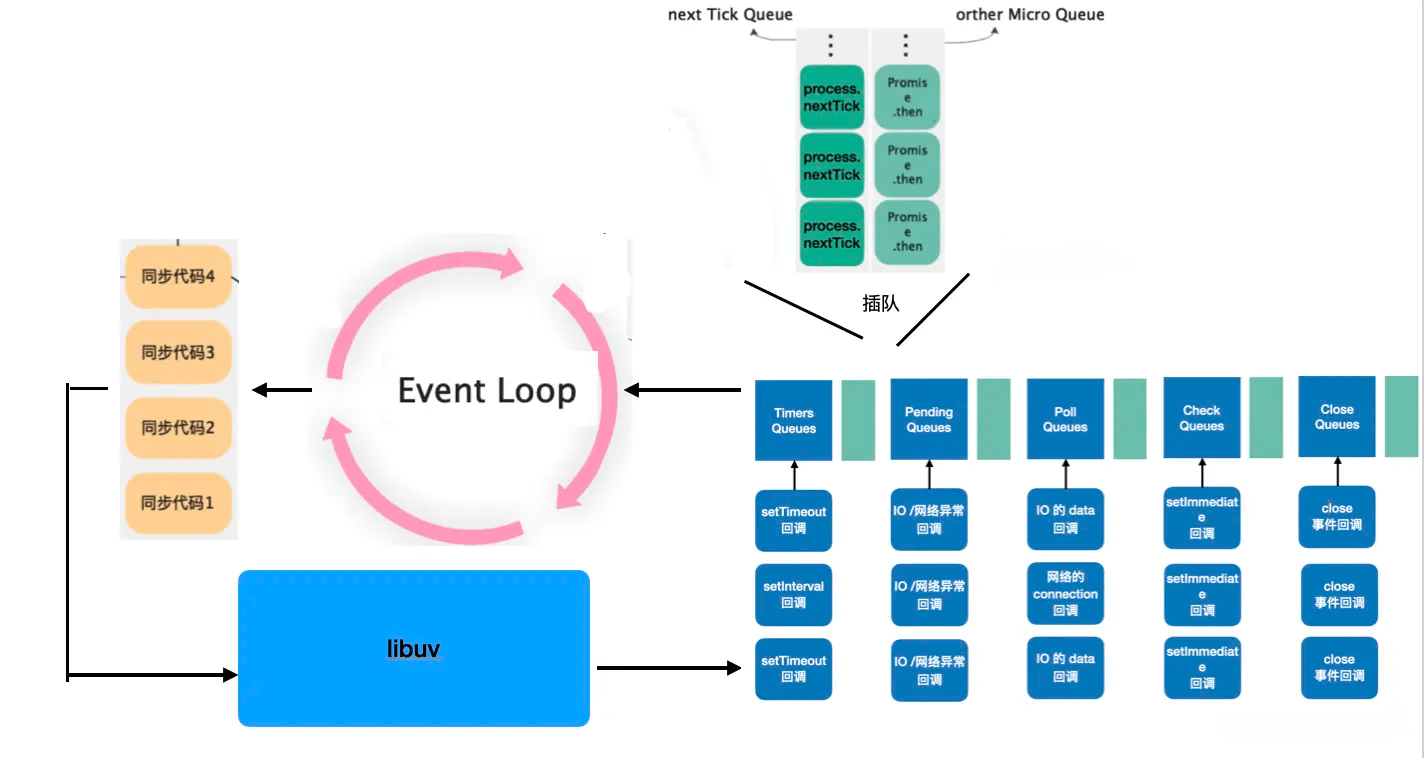
Node.js 宏任务之间的优先级划分:Timers > Pending > Poll > Check > Close。
- Timers Callback: 涉及到时间,肯定越早执行越准确,所以这个优先级最高很容易理解。
- Pending Callback:处理网络、IO 等异常时的回调,有的 unix 系统会等待发生错误的上报,所以得处理下。
- Poll Callback:处理 IO 的 data,网络的 connection,服务器主要处理的就是这个。
- Check Callback:执行 setImmediate 的回调,特点是刚执行完 IO 之后就能回调这个。
- Close Callback:关闭资源的回调,晚点执行影响也不到,优先级最低。
Node.js 微任务之间的优化及划分:process.nextTick > Promise。
2. Node.js 宏任务和微任务的执行时机
node 11 之前,Node.js 的 Event Loop 并不是浏览器那种一次执行一个宏任务,然后执行所有的微任务,而是执行完一定数量的 Timers 宏任务,再去执行所有微任务,然后再执行一定数量的 Pending 的宏任务,然后再去执行所有微任务,剩余的 Poll、Check、Close 的宏任务也是这样。node 11 之后改为了每个宏任务都执行所有微任务了。
而 Node.js 的 宏任务之间也是有优先级的,如果 Node.js 的 Event Loop 每次都是把当前优先级的所有宏任务跑完再去跑下一个优先级的宏任务,那么会导致 “饥饿” 状态的发生。如果某个阶段宏任务太多,下个阶段就一直执行不到了,所以每个类型的宏任务有个执行数量上限的机制,剩余的交给之后的 Event Loop 再继续执行。
最终表现就是:也就是执行一定数量的 Timers 宏任务,每个宏任务之间执行所有微任务,再一定数量的 Pending Callback 宏任务,每个宏任务之间再执行所有微任务。
三、Node.js 的多进程
1. 使用 child_process 方式手动创建进程
Node.js 程序通过 child_process 模块提供了衍生子进程的能力,child_process 提供多种子进程的创建方式:
- spawn 创建新进程,执行结果以流的形式返回,只能通过事件来获取结果数据,操作麻烦。
1 | const spawn = require('child_process').spawn; |
- execFile 创建新进程,按照其后面的 File 名字,执行一个可执行文件,可以带选项,以回调形式返回调用结果,可以得到完整数据,方便了很多。
1 | execFile('/path/to/node', ['--version'], function(error, stdout, stderr){ |
- exec 创建新进程,可以直接执行 shell 命令,简化了 shell 命令执行方式,执行结果以回调方式返回。
1 | exec('ls -al', function(error, stdout, stderr){ |
- fork 创建新进程,执行 node 程序,进程拥有完整的 V8 实例,创建后自动开启主进程到子进程的 IPC 通信,资源占用最多。
1 | var child = child_process.fork('./anotherSilentChild.js', { |
其中,spawn 是所有方法的基础,exec 底层是调用了 execFile。
2. 使用 cluster 方式半自动创建进程
以下是使用 Cluster 模块创建一个 http 服务集群的简单示例。示例中创建 Cluster 时使用同一个 Js 执行文件,在文件内使用 cluster.isPrimary 判断当前执行环境是在主进程还是子进程,如果是主进程则使用当前执行文件创建子进程实例,如果时子进程则进入子进程的业务处理流程。
1 | /* |
Cluster 模块允许设立一个主进程和若干个子进程,使用 child_process.fork() 在内部隐式创建子进程,由主进程监控和协调子进程的运行。
子进程之间采用进程间通信交换消息,Cluster 模块内置一个负载均衡器,采用 Round-robin 算法(轮流执行)协调各个子进程之间的负载。运行时,所有新建立的连接都由主进程完成,然后主进程再把 TCP 连接分配给指定的子进程。
使用集群创建的子进程可以使用同一个端口,Node.js 内部对 http/net 内置模块进行了特殊支持。Node.js 主进程负责监听目标端口,收到请求后根据负载均衡策略将请求分发给某一个子进程。
3. 使用基于 Cluster 封装的 PM2 工具全自动创建进程
PM2 是常用的 node 进程管理工具,它可以提供 node.js 应用管理能力,如自动重载、性能监控、负载均衡等。
其主要用于 独立应用 的进程化管理,在 Node.js 单机服务部署方面比较适合。可以用于生产环境下启动同个应用的多个实例提高 CPU 利用率、抗风险、热加载等能力。
由于是外部库,需要使用 npm 包管理器安装:
1 | $: npm install -g pm2 |
pm2 支持直接运行 server.js 启动项目,如下:
1 | $: pm2 start server.js |
即可启动 Node.js 应用,成功后会看到打印的信息:
1 | ┌──────────┬────┬─────────┬──────┬───────┬────────┬─────────┬────────┬─────┬───────────┬───────┬──────────┐ |
pm2 也支持配置文件启动,通过配置文件 ecosystem.config.js 可以定制 pm2 的各项参数:
1 | module.exports = { |
pm2 logs 日志功能也十分强大:
1 | $: pm2 logs |
II. Node.js 中进程池和线程池的适用场景
一般我们使用计算机执行的任务包含以下几种类型的任务:
计算密集型任务:任务包含大量计算,CPU 占用率高。
1
2
3
4
5
6const matrix = {};
for (let i = 0; i < 10000; i++) {
for (let j = 0; j < 10000; j++) {
matrix[`${i}${j}`] = i * j;
}
}IO 密集型任务:任务包含频繁的、持续的网络 IO 和磁盘 IO 的调用。
1
2const {copyFileSync, constants} = require('fs');
copyFileSync('big-file.zip', 'destination.zip');混合型任务:既有计算也有 IO。
一、进程池的适用场景
使用进程池的最大意义在于充分利用多核 CPU 资源,同时减少子进程创建和销毁的资源消耗。
进程是操作系统分配资源的基本单位,使用多进程架构能够更多的获取 CPU 时间、内存等资源。为了应对 CPU-Sensitive 场景,以及充分发挥 CPU 多核性能,Node 提供了 child_process 模块用于创建子进程。
子进程的创建和销毁需要较大的资源成本,因此池化子进程的创建和销毁过程,利用进程池来管理所有子进程。
除了这一点,Node.js 中子进程也是唯一的执行二进制文件的方式,Node.js 可通过流 (stdin/stdout/stderr) 或 IPC 和子进程通信。
通过 Stream 通信
1 | const {spawn} = require('child_process'); |
通过 IPC 通信
1 | const cp = require('child_process'); |
二、线程池的适用场景
使用线程池的最大意义在于多任务并行,为主线程降压,同时减少线程创建和销毁的资源消耗。单个 CPU 密集性的计算任务使用线程执行并不会更快,甚至线程的创建、销毁、上下文切换、线程通信、数据序列化等操作还会额外增加资源消耗。
但是如果一个计算机程序中有很多同一类型的阻塞任务需要执行,那么将他们交给线程池可以成倍的减少任务总的执行时间,因为在同一时刻多个线程在并行进行计算。如果多个任务只使用主线程执行,那么最终消耗的时间是线性叠加的,同时主线程阻塞之后也会影响其它任务的处理。
特别是对 Node.js 这种单主线程的语言来讲,主线程如果消耗了过多的时间来执行这些耗时任务,那么对整个 Node.js 单个进程实例的性能影响将是致命的。这些占用着 CPU 时间的操作将导致其它任务获取的 CPU 时间不足或 CPU 响应不够及时,被影响的任务将进入 “饥饿” 状态。
因此 Node.js 启动后主线程应尽量承担调度的角色,批量重型 CPU 占用任务的执行应交由额外的工作线程处理,主线程最后拿到工作线程的执行结果再返回给任务调用方。另一方面由于 IO 操作 Node.js 内部作了优化和支持,因此 IO 操作应该直接交给主线程,主线程再使用内部线程池处理。
Node.js 的异步能不能解决过多占用 CPU 任务的执行问题?
答案是:不能,过多的异步 CPU 占用任务会阻塞事件循环。
Node.js 的异步在 网络 IO / 磁盘 IO 处理上很有用,宏任务微任务系统 + 内部线程调用能分担主进程的执行压力。但是如果单独将 CPU 占用任务放入宏任务队列或微任务队列,对任务的执行速度提升没有任何帮助,只是一种任务调度方式的优化而已。
我们只是延迟了任务的执行或是将巨大任务分散成多个再分批执行,但是任务最终还是要在主线程被执行。如果这类任务过多,那么任务分片和延迟的效果将完全消失,一个任务可以,那十个一百个呢?量变将会引起质变。
以下是 Node.js 官方博客中的原文:
“如果你需要做更复杂的任务,拆分可能也不是一个好选项。这是因为拆分之后任务仍然在事件循环线程中执行,并且你无法利用机器的多核硬件能力。 请记住,事件循环线程只负责协调客户端的请求,而不是独自执行完所有任务。 对一个复杂的任务,最好把它从事件循环线程转移到工作线程池上。”
- 场景:间歇性让主进程 瘫痪
每一秒钟,主线程有一半时间被占用
1 | // this task costs 100ms |
- 场景:高频性让主进程 半瘫痪
每 200ms,主线程有一半时间被占用
1 | // this task costs 100ms |
以下是官方博客的原文摘录:
“因此,你应该保证永远不要阻塞事件轮询线程。换句话说,每个 JavaScript 回调应该快速完成。这些当然对于 await,Promise.then 也同样适用。”
III. 进程池
进程池是对进程的创建、执行任务、销毁等流程进行管控的一个应用或是一套程序逻辑。之所以称之为池是因为其内部包含多个进程实例,进程实例随时都在进程池内进行着状态流转,多个创建的实例可以被重复利用,而不是每次执行完一系列任务后就被销毁。因此,进程池的部分存在目的是为了减少进程创建的资源消耗。
此外进程池最重要的一个作用就是负责将任务分发给各个进程执行,各个进程的任务执行优先级取决于进程池上的负载均衡运算,由算法决定应该将当前任务派发给哪个进程,以达到最高的 CPU 和内存利用率。
假设有 A、B、C 三个进程,权重分别为 1、2、3,通过以下常见负载均衡算法的进程选择6次结果如下:
POLLING - 轮询:子进程轮流处理请求
原理:索引值递增,每次调用时会自动加 1,超出任务数组长度时会自动取模,保证平均调用。时间复杂度 O(n) = 1。
结果:ABCABC1
2
3
4
5
6
7
8
9module.exports = function (tasks, currentIndex, context) {
if (!tasks.length) return null;
const task = tasks[currentIndex];
context.currentIndex ++;
context.currentIndex %= tasks.length;
return task || null;
};WEIGHTS - 权重:子进程根据设置的权重来处理请求
原理:每个进程根据 (权重值 + (权重总和 * 随机因子)) 生成最终计算值,最终计算值中的最大值被命中。时间复杂度 O(n) = n。
结果:ABBCCC (仅代表理论概率)1
2
3
4
5
6
7
8
9
10
11
12
13
14module.exports = function (tasks, weightTotal, context) {
if (!tasks.length) return null;
let max = tasks[0].weight, maxIndex = 0, sum;
for (let i = 0; i < tasks.length; i++) {
sum = (tasks[i].weight || 0) + Math.random() * weightTotal;
if (sum >= max) {
max = sum;
maxIndex = i;
}
}
return tasks[maxIndex];
};RANDOM - 随机:子进程随机处理请求
原理:随机函数在 [0, length) 中任意选取一个索引即可。时间复杂度 O(n) = 1。
结果:ABCABC (仅代表理论概率)1
2
3
4
5
6
7module.exports = function (tasks) {
const length = tasks.length;
const target = tasks[Math.floor(Math.random() * length)];
return target || null;
};WEIGHTS_POLLING - 权重轮询:权重轮询策略与轮询策略类似,但是权重轮询策略会根据权重来计算子进程的轮询次数,从而稳定每个子进程的平均处理请求数量。
原理:类似轮询策略,不过轮询的区间为:[最小权重值, 权重总和],根据各项权重累加值进行命中区间计算。每次调用时权重索引会自动加 1,超出权重总和时会自动取模。时间复杂度 O(n) = n。
结果:ABBCCC1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18module.exports = function (tasks, weightIndex, weightTotal, context) {
if (!tasks.length) return null;
let weight = 0;
let task;
for (let i = 0; i < tasks.length; i++) {
weight += tasks[i].weight || 0;
if (weight >= weightIndex) {
task = tasks[i];
break;
}
}
context.weightIndex += 1;
context.weightIndex %= (weightTotal + 1);
return task;
};WEIGHTS_RANDOM - 权重随机:权重随机策略与随机策略类似,但是权重随机策略会根据权重来计算子进程的随机次数,从而稳定每个子进程的平均处理请求数量。
原理:由 (权重总和 * 随机因子) 产生计算值,将各项权重值与其相减,第一个不大于零的最终值即被命中。时间复杂度 O(n) = n
结果:ABBCCC (仅代表理论概率)1
2
3
4
5
6
7
8
9
10
11
12
13
14module.exports = function (tasks, weightTotal) {
let task;
let weight = Math.ceil(Math.random() * weightTotal);
for (let i = 0; i < tasks.length; i++) {
weight -= tasks[i].weight || 0;
if (weight <= 0) {
task = tasks[i];
break;
}
}
return task || null;
};SPECIFY - 指定:子进程根据指定的进程 id 处理请求
MINIMUM_CONNECTION - 最小连接数:选择子进程上具有最小连接活动数量的子进程处理请求。
WEIGHTS_MINIMUM_CONNECTION - 权重最小连接数:权重最小连接数策略与最小连接数策略类似,不过各个子进程被选中的概率由连接数和权重共同决定。
一、要点
「 对单一任务的控制不重要,对单个进程宏观的资源占用更需关注 」
二、流程设计
进程池架构图参考之前的进程管理工具开发相关 文章,本文只需关注进程池部分。
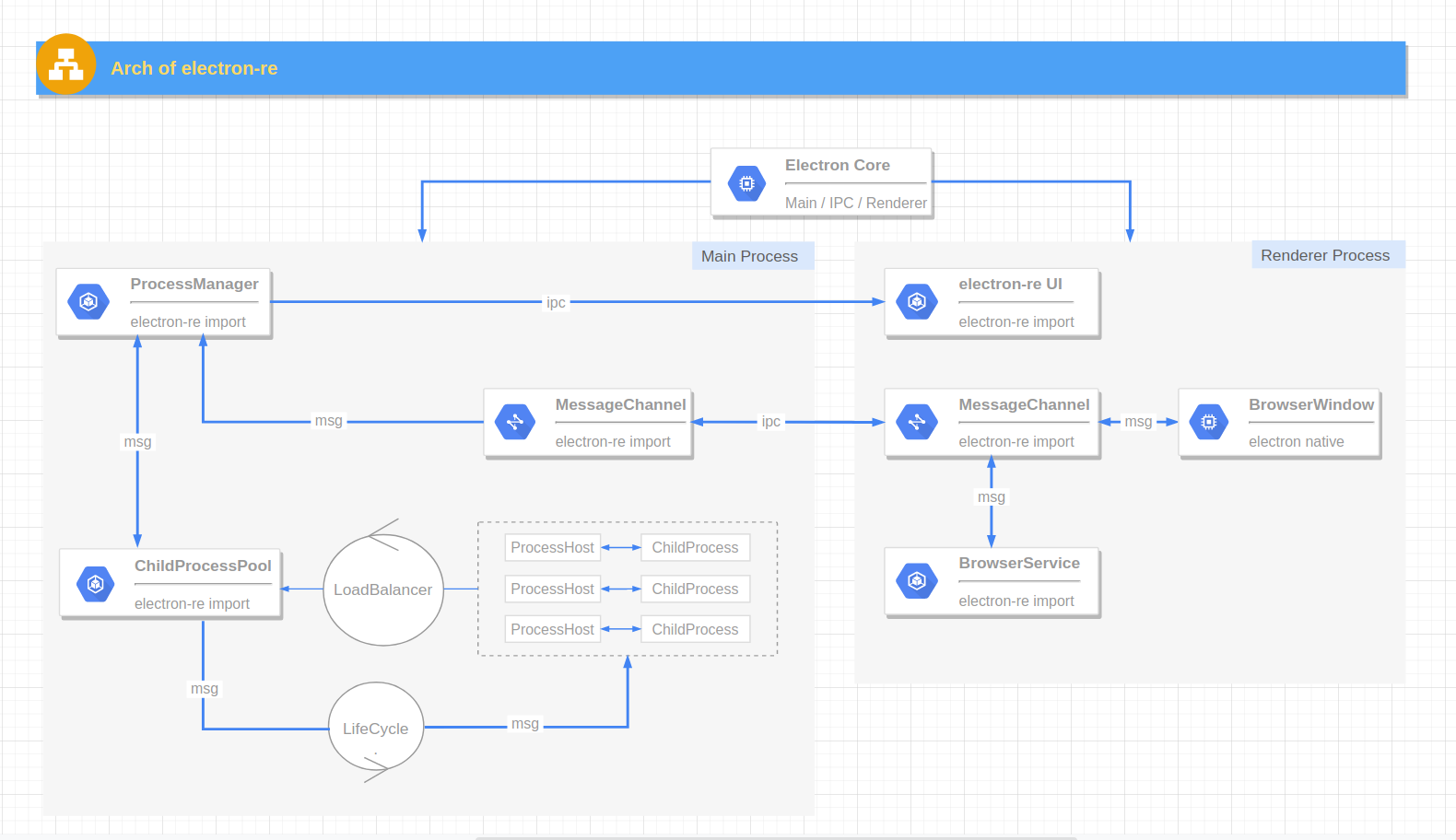
1. 关键流程
- 进程池创建进程时会初始化进程实例内的 ProcessHost 事务对象,进程实例向事务对象注册多种任务监听器。
- 用户向进程池发起单个任务调用请求,可传入进程绑定的 ID 和指定的任务名。
- 判断用户是否传入 ID 参数指定使用某个进程执行任务,如果未指定 ID:
- 进程池判断当前进程池进程数量是否已超过最大值,如果未超过则创建新进程,用此进程处理当前任务,并将进程放入进程池。
- 如果进程池进程数量已达最大值,则根据负载均衡算法选择一个进程处理当前任务。
- 指定 ID 时:
- 通过用户传入的 ID 参数找到对应进程,将任务分发给此进程执行。
- 如果未找到 ID 所对应的进程,则向用户抛出异常。
- 任务由进程池派发给目标进程后,ProcessHost 事务对象会根据该任务的任务名触发子进程内的监听器。
- 子进程内的监听器函数可执行同步任务和异步任务,异步任务返回 Promise 对象,同步任务返回值。
- ProcessHost 事务对象的监听器函数执行完毕后,会将任务结果返回给进程池,进程池再将结果通过异步回调函数返回给用户。
- 用户也可向进程池所有子进程发起个任务调用请求,最终将会通过 Promise 的返回所有子进程的任务执行结果。
2. 名词解释
- ProcessHost 事务中心:运行在子进程中,用于事件触发以及和主进程通信。开发者在子进程执行文件中向其注册多个具有特定任务名的任务事件,主进程会向某个子进程发送任务请求,并由事务中心调用指定的事件监听器处理请求。
- LoadBalancer 负载均衡器:用于选择一个进程处理任务,可根据不同的负载均衡算法实现不同的选择策略。
- LifeCycle: 设计之初用于管控子进程的智能启停,某个进程在长时间未被使用时进入休眠状态,当有新任务到来时再唤醒进程。目前还有些难点需要解决,比如进程的唤醒和休眠不好实现,进程的使用情况不好统计,该功能暂时不可用。
三、进程池使用方式
1. 创建进程池
main.js
1 | const { ChildProcessPool, LoadBalancer } = require('electron-re'); |
child.js
1 | const { ProcessHost } = require('electron-re'); |
2. 向一个子进程发送任务请求
1 | processPool.send('test1', { value: "test1"}).then((result) => { |
3. 向所有子进程发送任务请求
1 | processPool.sendToAll('test1', { value: "test1"}).then((results) => { |
四、进程池实际使用场景
1. Electron 网页代理工具中多进程的应用
1)基本代理原理:

2)单进程下客户端执行原理:
- 通过用户预先保存的服务器配置信息,使用 node.js 子进程来启动 ss-local 可执行文件建立和 ss 服务器的连接来代理用户本地电脑的流量,每个子进程占用一个 socket 端口。
- 其它支持 socks5 代理的 proxy 工具比如:浏览器上的 SwitchOmega 插件会和这个端口的 tcp 服务建立连接,将 tcp 流量加密后通过代理服务器转发给我们需要访问的目标服务器。
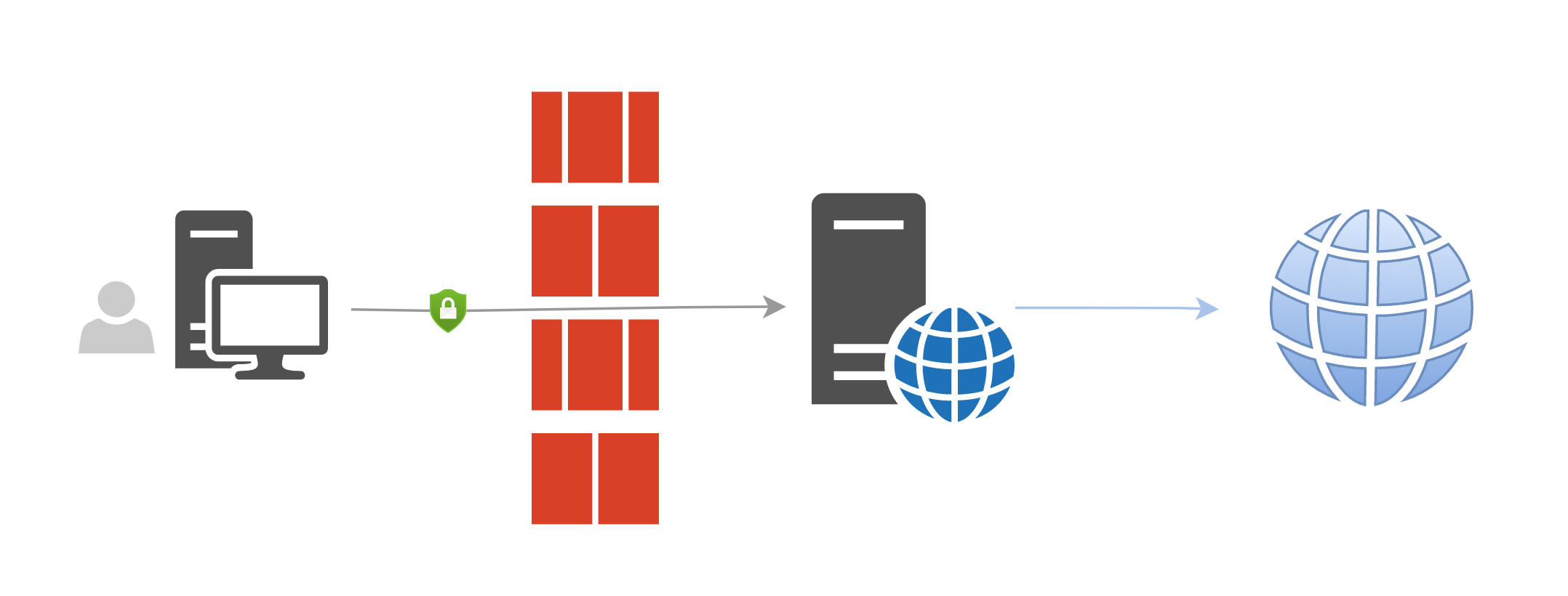
3)多进程下客户端执行原理:
以上描述的是客户端连接单个节点的工作模式,节点订阅组中的负载均衡模式需要同时启动多个子进程,每个子进程启动 ss-local 执行文件占用一个本地端口并连接到远端一个服务器节点。
每个子进程启动时选择的端口是会变化的,因为某些端口可能已经被系统占用,程序需要先选择未被使用的端口。并且浏览器 proxy 工具也不可能同时连接到我们本地启动的子进程上的多个 ss-local 服务上。因此需要一个占用固定端口的中间节点接收 proxy 工具发出的连接请求,然后按照某种分发规则将 tcp 流量转发到各个子进程的 ss-local 服务的端口上。
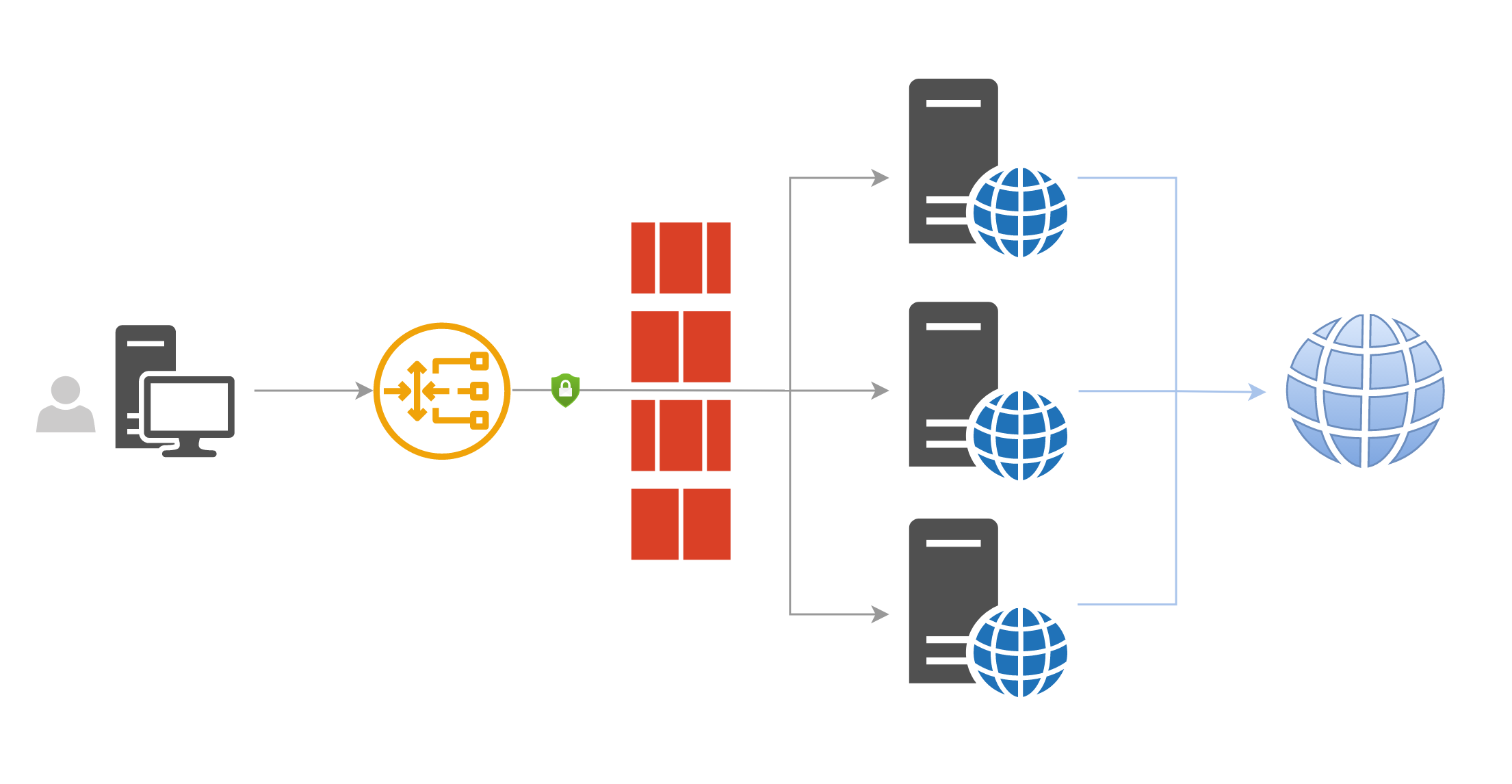
2. 多进程文件分片上传 Electron 客户端
之前做过一个支持 SMB 协议多文件分片上传的客户端,Node.js 端的上传任务管理、IO 操作等都使用多进程实现过一版本,不过是在 gitlab 实验分支自己搞得(逃)。
IV. 线程池
为了减小 CPU 密集型任务计算的系统开销,Node.js 引入了新的特性:工作线程 worker_threads,其首次在 v10.5.0 作为实验性功能出现。通过 worker_threads 可以在进程内创建多个线程,主线程与 worker 线程使用 parentPort 通信,worker 线程之间可通过 MessageChannel 直接通信。worker_threads 做为开发者使用线程的重要特性,在 v12.11.0 稳定版已经能正常在生产环境使用了。
但是线程的创建需要额外的 CPU 和内存资源,如果要多次使用一个线程的话,应该将其保存起来,当该线程完全不使用时需要及时关闭以减少内存占用。想象我们在需要使用线程时直接创建,使用完后立刻销毁,可能线程自身的创建和销毁成本已经超过了使用线程本身节省下的资源成本。Node.js 内部虽然有使用线程池,但是对于开发者而言是完全透明不可见的,因此封装一个能够维护线程生命周期的线程池工具的重要性就体现了。
为了强化多异步任务的调度,线程池除了提供维护线程的能力,也提供维护任务队列的能力。当发送请求给线程池让其执行一个异步任务时,如果线程池内没有空闲线程,那该任务就会被直接丢弃了,显然这不是想要的效果。
因此可以考虑为线程池添加一个任务队列的调度逻辑:当线程池没有空闲线程时,将该任务放入待执行任务队列 (FIFO),线程池在某个时机取出任务交由某个空闲线程执行,执行完成后触发异步回调函数,将执行结果返回给请求调用方。但是线程池的任务队列内的任务数量应该考虑限制到一个特殊值,防止线程池负载过大影响 Node.js 应用整体运行性能。
一、要点
「 对单一任务的控制重要,对单个线程的资源占用无需关注 」
二、详细设计
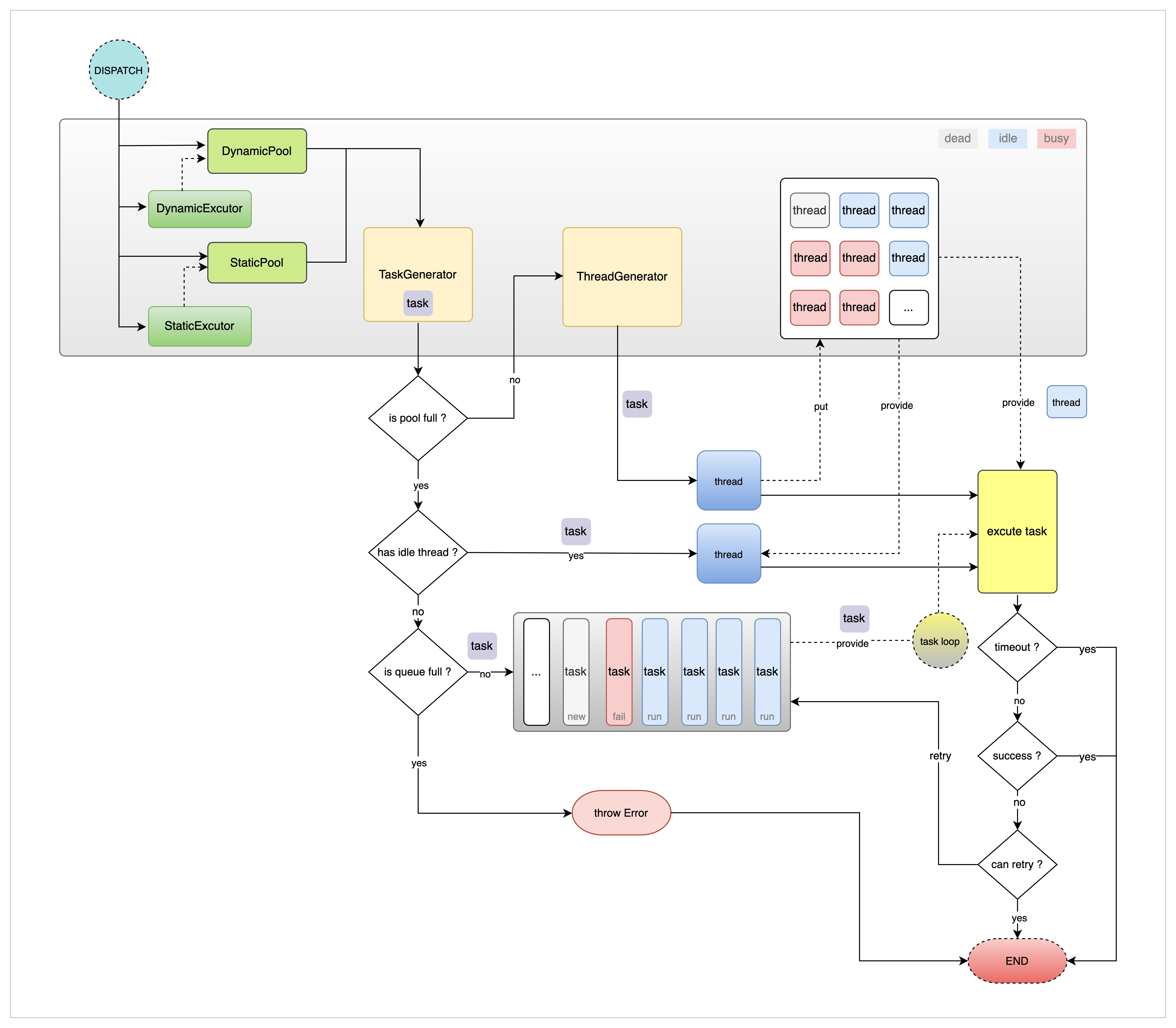
任务流转过程
- 调用者可通过
StaticPool/StaticExcutor/DynamicPool/DynamicExcutor实例向线程池派发任务(以下有关键名词说明),各种实例的之间最大的不同点就是参数动态化能力。 - 任务由线程池内部生成,生成后任务做为主要的流转载体,一方面承载用户传入的任务计算参数,另一方面记录任务流转过程中的状态变化,比如:任务状态、开始时间、结束时间、任务 ID、任务重试次数、任务是否支持重试、任务类型等。
- 任务生成后,首先判断当前线程池的线程数是否已达上限,如果未达上限,则新建线程并将其放入线程存储区,然后使用该线程直接执行当前任务。
- 如果线程池线程数超限,则判断是否有未执行任务的空闲线程,拿到空闲线程后,使用该线程直接执行当前任务。
- 如果没有空闲线程,则判断当前等待任务队列是否已满,任务队列已满则抛出错误,第一时间让调用者感知任务未执行成功。
- 如果任务队列未满的话,将该任务放入任务队列,等待任务循环系统取出将其执行。
- 以上 4/5/6 步的三种情况下任务执行后,判断该任务是否执行成功,成功时触发成功的回调函数,Promise 状态为 fullfilled。如果失败,则判断是否支持重试,支持重试的情况下,将该任务重试次数 + 1 后重新放入任务队列尾部。任务不支持重试的情况下,直接失败,并触发失败的异步回调函数,Promise 状态为 rejected。
- 整个线程池生命周期中,存在一个任务循环系统,以一定的周期频率从任务队列首部获取任务,并从线程存储区域获取空闲线程后使用该线程执行任务,该流程也符合第 7 步的描述。
- 任务循环系统除了取任务执行,如果线程池设置了任务超时时间的话,也会判断正在执行中的任务是否超时,超时后会终止该线程的所有运行中的代码。
模块说明
- StaticPool
- 定义:静态线程池,可使用固定的
execFunction/execString/execFile执行参数来启动工作线程,执行参数在进程池创建后不能更改。 - 进程池创建之后除了执行参数不可变外,其它参数比如:任务超时时间、任务重试次数、线程池任务轮询间隔时间、最大任务数、最大线程数、是否懒创建线程等都可以通过 API 随时更改。
- 定义:静态线程池,可使用固定的
- StaticExcutor
- 定义:静态线程池的执行器实例,继承所属线程池的固定执行参数
execFunction/execString/execFile且不可更改。 - 执行器实例创建之后除了执行参数不可变外,其它参数比如:任务超时时间、任务重试次数、transferList 等都可以通过 API 随时更改。
- 静态线程池的各个执行器实例的参数设置互不影响,参数默认继承于所属线程池,参数在执行器上更改后具有比所属线程池同名参数更高的优先级。
- 定义:静态线程池的执行器实例,继承所属线程池的固定执行参数
- DynamicPool
- 定义:动态线程池,无需使用
execFunction/execString/execFile执行参数即可创建线程池。执行参数在调用exec()方法时动态传入,因此执行参数可能不固定。 - 线程池创建之后执行参数默认为
null,其它参数比如:任务超时时间、任务重试次数、transferList 等都可以通过 API 随时更改。
- 定义:动态线程池,无需使用
- DynamicExcutor
- 定义:动态线程池的执行器实例,继承所属线程池的其它参数,执行参数为
null。 - 执行器实例创建之后,其它参数比如:任务超时时间、任务重试次数、transferList 等都可以通过 API 随时更改。
- 动态线程池的各个执行器实例的参数设置互不影响,参数默认继承于所属线程池,参数在执行器上更改后具有比所属线程池同名参数更高的优先级。
- 动态执行器实例在执行任务之前需要先设置执行参数
execFunction/execString/execFile,执行参数可以随时改变。
- 定义:动态线程池的执行器实例,继承所属线程池的其它参数,执行参数为
- ThreadGenerator
- 定义:线程创建的工厂方法,会进行参数校验。
- Thread
- 定义:线程实例,内部简单封装了
worker_threadsAPI。
- 定义:线程实例,内部简单封装了
- TaskGenerator
- 定义:任务创建的工厂方法,会进行参数校验。
- Task
- 定义:单个任务,记录了任务执行状态、任务开始结束时间、任务重试次数、任务携带参数等。
- TaskQueue
- 定义:任务队列,在数组中存放任务,以先入先出方式 (FIFO) 向线程池提供任务,使用 Map 来存储 taskId 和 task 之间的映射关系。
- Task Loop
- 任务循环,每个循环的默认时间间隔为 2S,每次循环中会处理超时任务、将新任务派发给空闲线程等。
三、线程池使用方式
1. 创建静态线程池
main.js
1 | const { StaticThreadPool } = require(`electron-re`); |
worker.js
1 | const fibonaccis = (n) => { |
2. 使用静态线程池发送任务请求
1 | threadPool.exec(15).then((res) => { |
3. 动态线程池和动态执行器
1 | const { DynamicThreadPool } = require(`electron-re`); |
四、线程池实际使用场景
暂未在项目中实际使用,可考虑在前端图片像素处理、音视频转码处理等 CPU 密集性任务中进行实践。
这里有篇文章写了 web_worker 的一些应用场景,web_worker 和 worker_threads 是类似的,宿主环境不同,一些权限和能力的不同而已。
V. 单元测试用例覆盖度报告生成
对于工具库的开发而言,单元测试的必要性还是挺大的,一方面它编写起来相对简单快捷,与页面组件代码的测试相比,库的测试只是一些代码运行逻辑测试,仿真环境模拟起来比较容易。
另一方面,单元测试更多的优势是体现在多次迭代开发过程中,每次改动代码均可通过运行测试样例来快速验证逻辑正确性,减少了开发者的自测成本,同时基本保证成品质量。
一、使用 mocha 框架编写单元测试
mocha 作为一个易用的断言测试框架,使用方式非常简单,支持异步测试和同步代码测试:
1 | const threadPool = new StaticThreadPool( |
运行测试后可以在命令行输出用例通过情况:
1 | app ready => |
二、使用 nyc 一键生成测试覆盖度报告
nyc 作为一个自动化测试覆盖度生成工具,和 mocha 一起使用,可支持一键生成覆盖度报告:
在 package.json 中声明相关的测试命令:
1 | { |
新建 nyc 配置文件,配置输出格式、路径等:
1 | { |
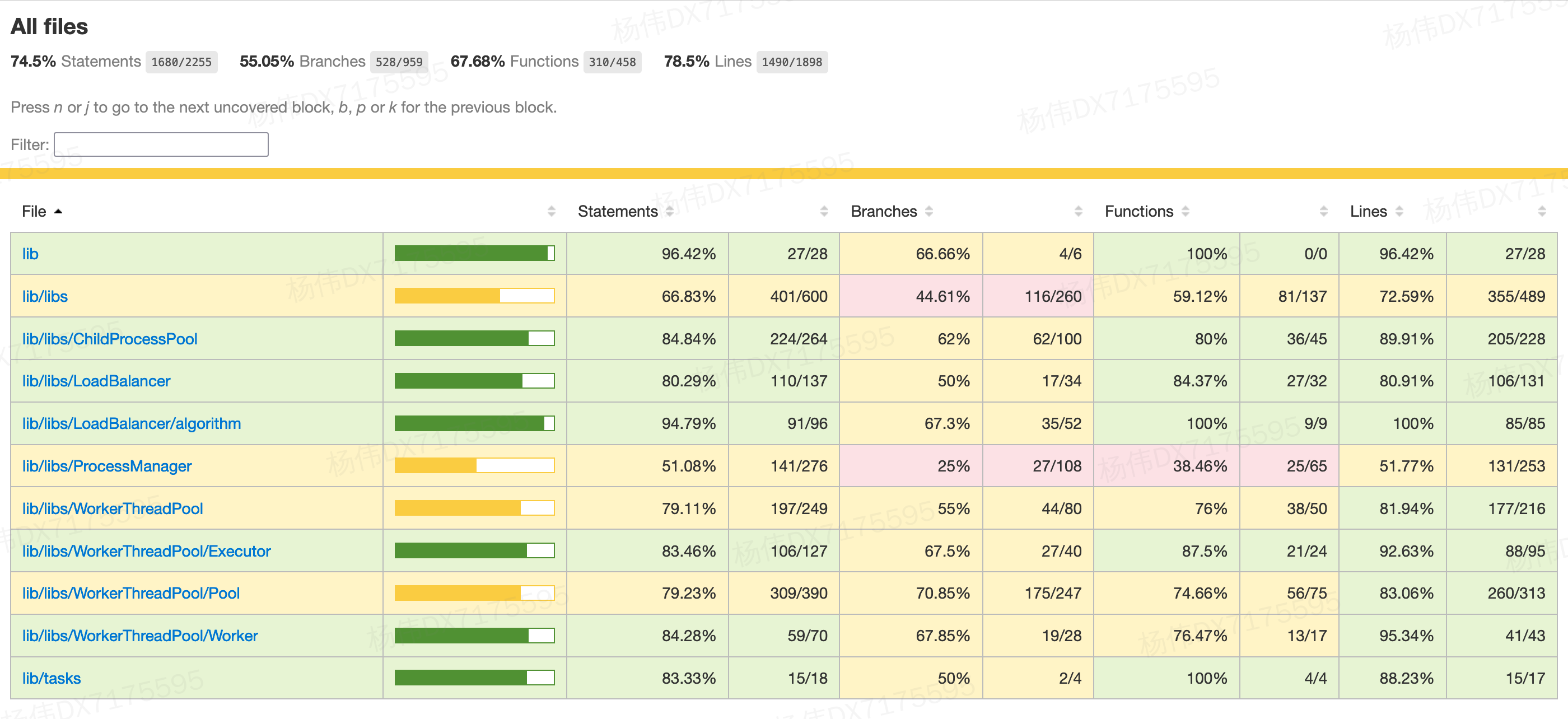
可生成 HTML 文件用于显示测试用例覆盖度详细情况:
VI. 结尾
最开始 项目 做为 Electron 应用开发的一个工具集提供了 BrowserService / ChildProcessPool / 简易进程监控 UI / 进程间通信 等功能,线程池的加入其实是当初没有计划的,而且线程池本身是独立的,不依赖 electron-re 中其它模块功能,之后应该会被独立出去。
进程池和线程池的实现方案上还需完善。
比如进程池未支持子进程空闲时自动退出以解除资源占用,当时做了另一版监听 ProcessHost 的任务执行情况来让子进程空闲时休眠,想通过此方式节省资源占用。不过由于没有 node.js API 级别的支持以分辨子进程空闲的情况,并且子进程的休眠 / 唤醒功能比较鸡肋 (有尝试通过向子进程发送 SIGSTOP/SIGCONT 信号实现),最终这个特性被废除了。
后面可以考虑支持 CPU/Memory 的负载均衡算法,目前已经通过项目中的 ProcessManager 模块来实现资源占用情况采集了。
线程池方面相对的可用度还是较高,提供了 pool/excutor 两个层级的调用管理,支持链式调用,在一些需要提升数据传输性能的场景支持 transferList 方式避免数据克隆。相对于其它开源 Node 线程池方案,着重对任务队列功能进行了加强,支持任务重试、任务超时等功能。
VII. 参考链接
- Node.js Doc - worker_threads
- Node.js Doc - child_process
- Node.js multithreading: Worker threads and why they matter
- 不要阻塞你的事件循环(或是工作线程池)
- Node.js 之深入理解特性
- Java 线程池实现原理及其在美团业务中的实践
- 美团动态线程池实践
- Python 的进程、线程和协程的适用场景和使用技巧